Train#
Training a network involves two steps:
Make a dataset from exported annotations.
Configure and train a network.
Make a dataset from exported annotations#
Training requires data in a specific format in which the audio is split into different parts for use during training to optimize the network and after training to evaluate network performance. The GUI automates the generation of these datasets from audio annotated using the GUI. Alternatively, you can also use your existing annotations or make a dataset yourself. For details on the data format itself, see here.
In the GUI, make a dataset via DAS/Make dataset for training. This will first ask you to select the folder with the exported audio and annotations, and then present a dialog with options for customizing the dataset creation:
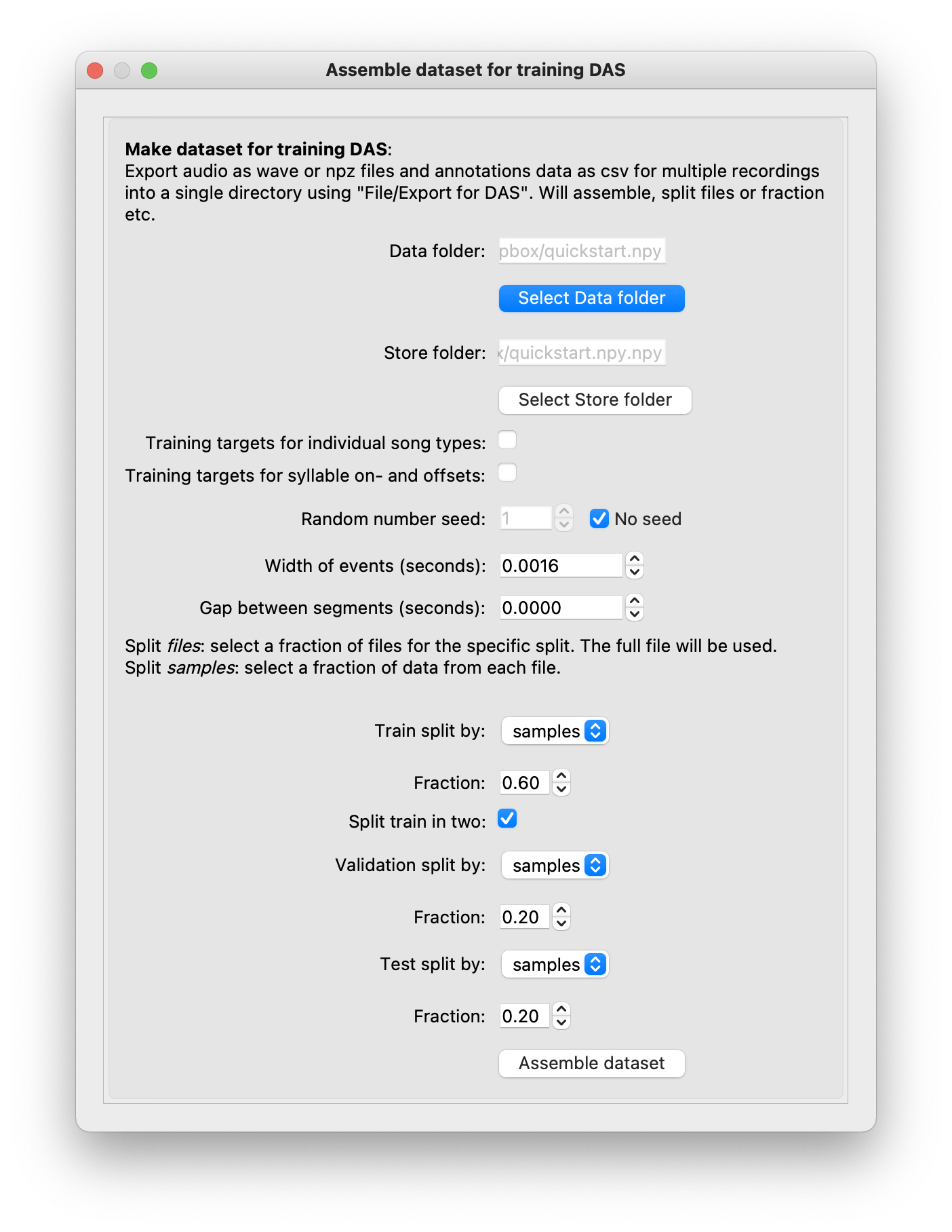
Dialog for customizing a dataset for training.#
Data folder & Store folder: The data folder contains your exported annotations (annotations as
*_annotations.csv, audio as*.npzor*.wav). From these annotations, the dataset will be created and save in the store folder. By default, the store folder is the data folder with.npyappended. Important: You can change the name of the store folder but the data folder must end in.npyfor DAS to recognize the dataset.Make individual training targets: By default, the dataset will contain targets for a single network that recognizes all annotated song types. To be able to train a network for specific song types, enable this option. Training specific networks for individual song types, instead of a single network for all song types, can sometimes improve performance.
Width of events (seconds): Events are defined by a single time point — to make training more robust, events should are represented by a Gaussian with specified width (standard deviation).
Gap between segments (seconds): To simplify post processing of segments, in particular for birdsong with its many syllable types, we found that introducing brief gaps between individual syllables (segments) simplifies post-processing the inferred annotations.
Train/validation/test splits: Typically, the data is split into three parts, which are used during different phases of training:
train: optimize the network parameters during training
validation: monitor network performance during training and steer training (stop early or adjust learning rate)
test: independent data to assess network performance after training. This can be omitted when training on very little data.
Splits can be generated using a mixture of two strategies:
Split by files: Use a fraction of files in the data folder for the specific split. Full files will be used for the split. Only works if you have multiple annotated files.
Split by samples: Select a fraction of data from every file in the data folder.
Recommendation: If you have enough files, split train and validation by samples and split test by files that come from different individuals. That way your test set assesses how well the network generalizes to new individuals. If you have too few files or the specific song types do not appear in all files, split by samples.
Note
The dataset can be inspected using the inspect_dataset notebook if you are curious or if training fails.
Train DAS using the GUI#
Configure a network and start training via DAS/Train. This will ask you select the dataset folder ending in .npy that you just created. Then, a dialog will allow you to customize the network to be trained.
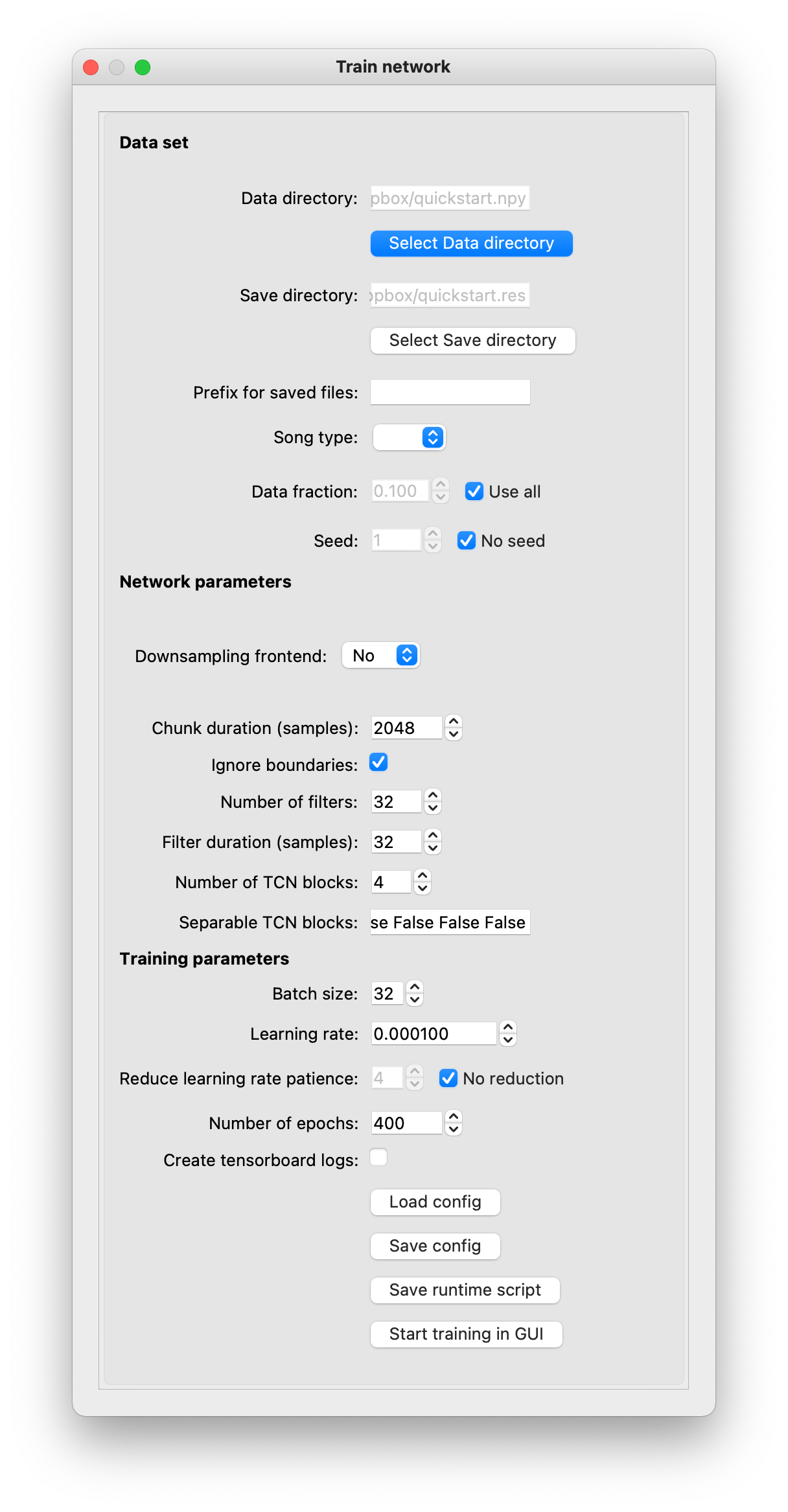
Train options#
Options are grouped into three sections:
Data set:
Data folder: Folder with the assembled annotations. Name must end in
.npySave folder: Folder for saving the files generated during training (network model and parameters, test results). Defaults to the name of the data folder, with the suffix
.npyreplaced by.res.Prefix for saved files: Files generated during training are named based on the time the training started (
YYYYMMDD_hhmmss). You can add an informative prefix, for instancepulsesine. An underscore will be interleaved between the prefix and the timestamp. The resulting files will then start with something likepulsesine_20201012_125534_.Song type: Select the song type you want the network to recognize. Defaults to blank (all annotated song types). Will be populated with training targets if you select Make individual training targets during dataset assembly.
Data fraction & Seed: Use a random subset of the data from the training and validation splits. The seed gives you reproducibility. This does not affect the test set. That way you can train a network on different subsets of your data and test on the same dataset.
Network parameters:
Downsampling frontend: Trainable frontend initialized with STFT filters. Improves performance and speeds up training and inference for signals with high carrier frequencies relative to the amplitude or frequency modulation spectra - for instance ultrasonic vocalizations or bird song. Only works with single-channel, not with multi-channel audio.
Number of filters: Number of filters per layer in the frontend.
Filter duration (samples): Duration of the filters in the frontend.
Downsample factor: The output of the STFT will be downsampled by that factor (only every Nth sample will be taken) before being fed into the main TCN.
Chunk duration (samples): Number of samples processed at once. Defines an upper bound to the audio context available to the network.
Number of filters: Number of filters in each layer of the network. Vary between 16 and 32. Fewer typically decrease performance, more rarely help.
Filter duration (samples): Duration of each filter in samples. Should correspond to the duration of the lowest level song feature (e.g. the carrier if training on raw audio without a downsampling frontend).
Number of TCN blocks: Number of TCN blocks in the network. Deeper networks (more TCN blocks) allow extracting more derived sound features. We found values between 2 and 6 blocks to work well.
Separable TCN blocks: Useful only for multi-channel audio. Whether the convolutions in individual TCN blocks should be separable by time and channel: In a separable convolution, each audio channel is first filtered with a set of filters and then the filtered channels are combined with a second set of filters. Allows sharing filters across channels - the idea is that some filtering operations should be applied to each channel equally. The first one or two TCN blocks can be set to use separable convolutions for multi-channel audio. Should be a space-separated sequence of
TrueorFalsewith the same length as the number of TCN blocks. For instance, a 5-block network with the first two blocks set to use separable convolutions would be:True True False False False.
Training parameters:
Learning rate: Determines by how much the parameters are updated in every step. Too small, and performance will take very long to improve, too large and performance will diverge. The optimal value depends on the network and data size but performance is relatively robust to the specific choice of value. Values between 0.1 and 0.0001 typically work.
Reduce learning rate patience: The learning rate can be reduced automatically if the performance on the validation set does not increase for the specified number of epochs. We did not find this to improve or speed up training much.
Number of epochs: Maximum number of training epochs. For training with small data sets during fast training, 10 epochs are typically sufficient. For training on larger datasets leave as is. Training will stop early if the performance on the validation set did not increase in the last 20 epochs.
Create tensorboard logs: Create tensorboard logs for monitoring training.
Training can be started locally in a separate process or a script can be generated for training on the command line, for instance on a cluster.
Train from the command line#
The datasets are portable—you can copy the folder with the dataset to another computer with a GPU and run training from the GUI there. If that machine cannot be used with a GUI—for instance if it’s a linux server, the training and network configuration can be exported via the dialog as a command line script and executed via a terminal.
The script uses the command-line interface das train for training DAS (see also train using command-line scripts) and its contents will look like this:
das train --data-dir /Users/DAS/tutorial/gui_demo.npy --save-dir /Users/DAS/tutorial/gui_demo.res --nb-hist 256 --ignore-boundaries True --nb-filters 32 --kernel-size 32 --nb-conv 3 --use-separable False False False --learning-rate 0.0001 --nb-epoch 400 --model-name tcn --no-reduce-lr --no-tensorboard
For the script to work on a different machine, it likely require some edits:
--data-dirneeds to point to the dataset folder ending in.npyon the remote machine.--save-dirneeds to point to a valid, writable path.Add a line to activate a specific conda environment before running
das train. For instance,conda activate das.Activate linux modules, for instance to enable CUDA; or specify parameters for your job scheduler.
Files generated during training#
The following files will be created in the save folder:
_model.h5: trained network model._params.yaml: info on data formats etc._results.h5: test results.
The _model.h5 and _params.yaml are required for using the network for predictions and need to be copied to your local machine if you train remotely.