Annotate song#
Initialize or edit song types#
Song types need to be “registered” for annotation. DAS discriminates two categories of song types:
Events are defined by a single time of occurrence. Drosophila pulse song is a song type of the event category.
Segments are song types that extend over time and are defined by a start and a stop time. Drosophila sine song and the syllables of mouse and bird vocalizations fall into the segment category.
If you load audio that has been annotated before, the annotations will be loaded with the audio. Song types can be added, renamed, and deleted via Annotations/Add or edit song types.
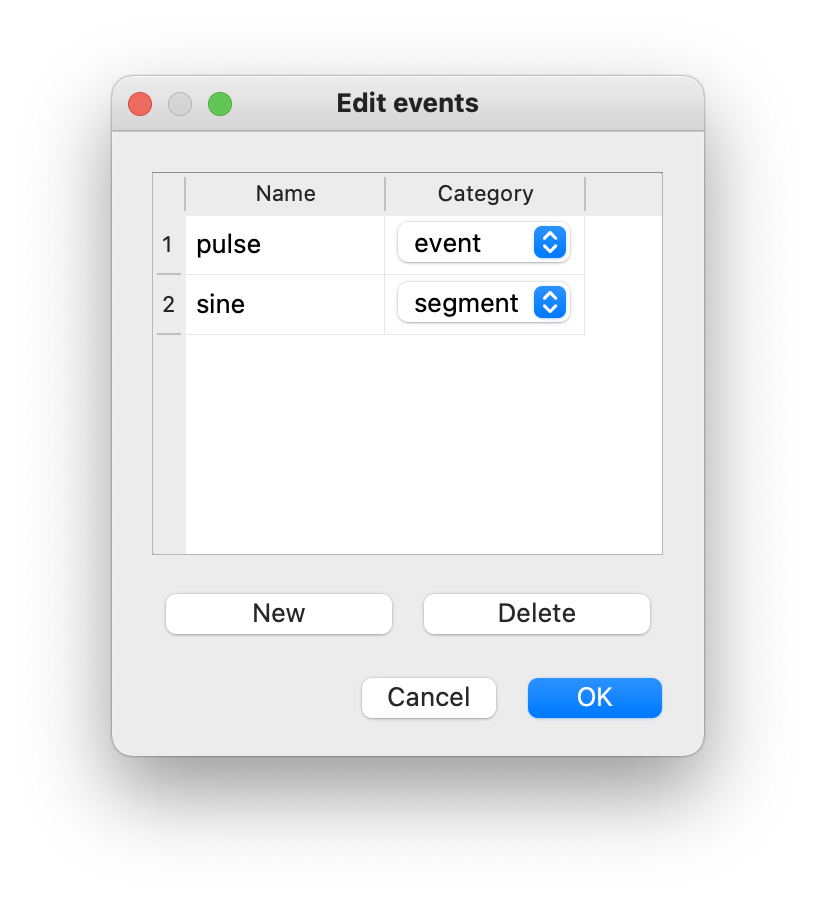
Create, rename or delete song types for annotation.#
Create annotations manually#
The registered song types can now be activated for annotation using the dropdown menu on the top left of the main window, or via the number keys indicated in the dropdown menu.
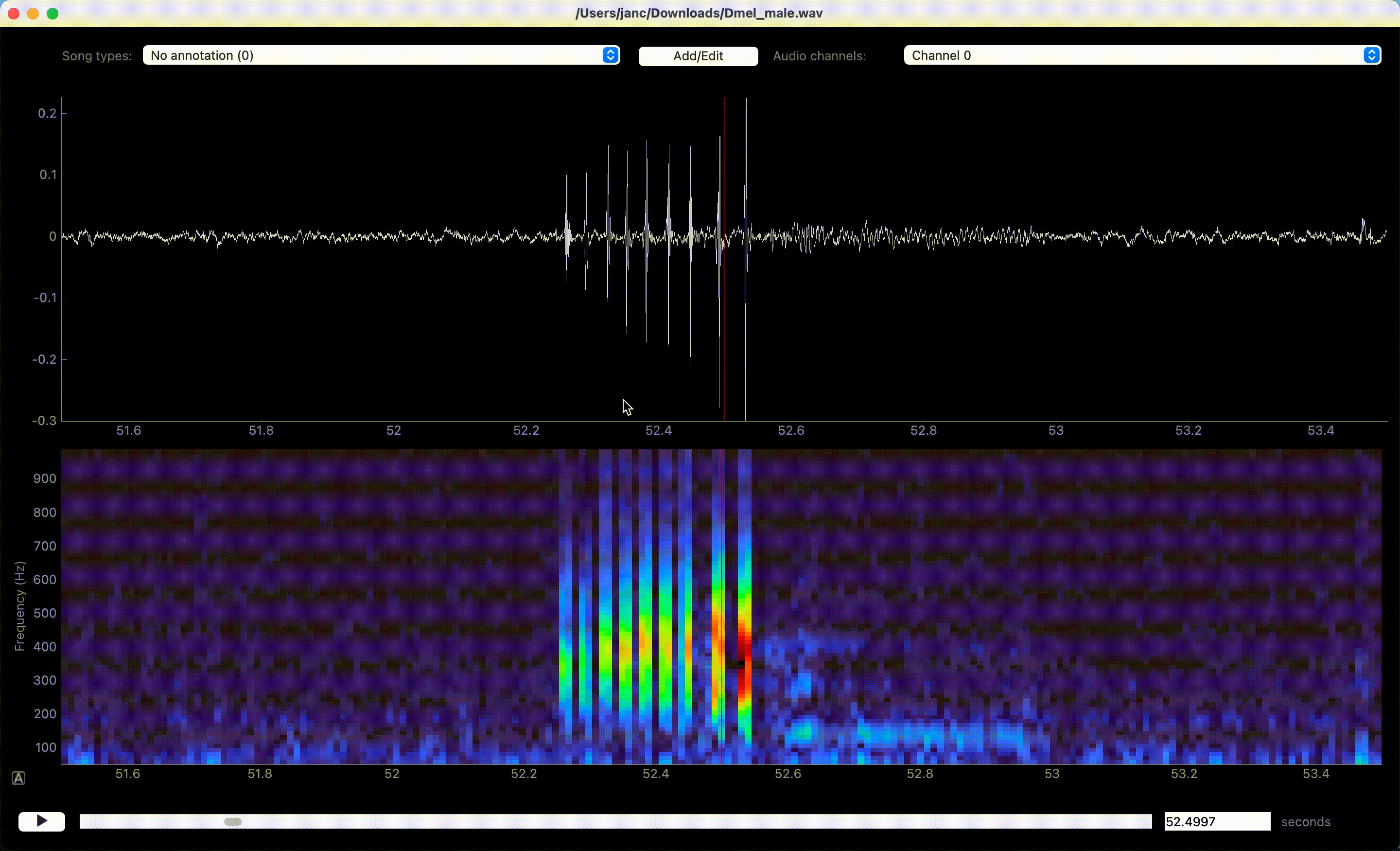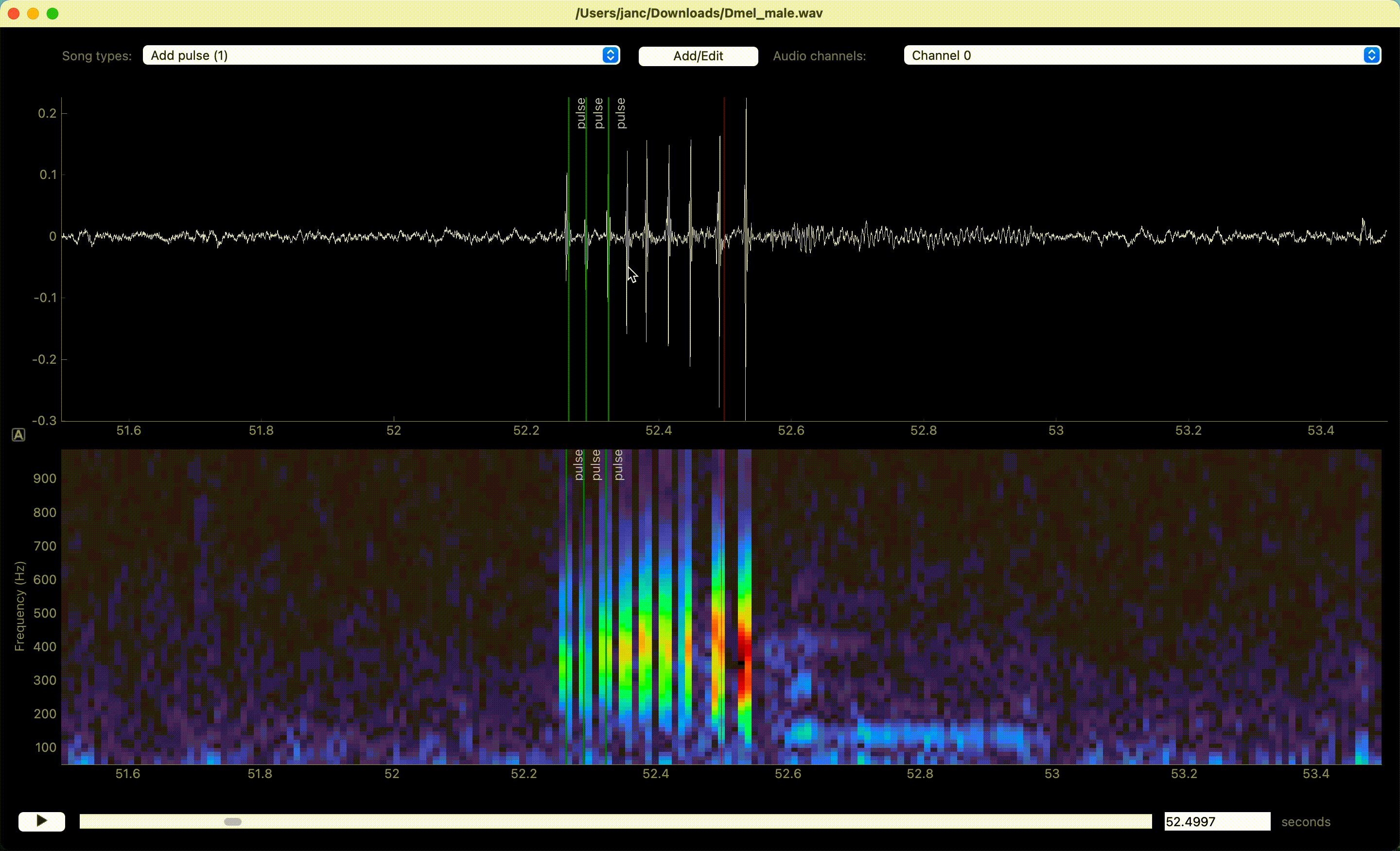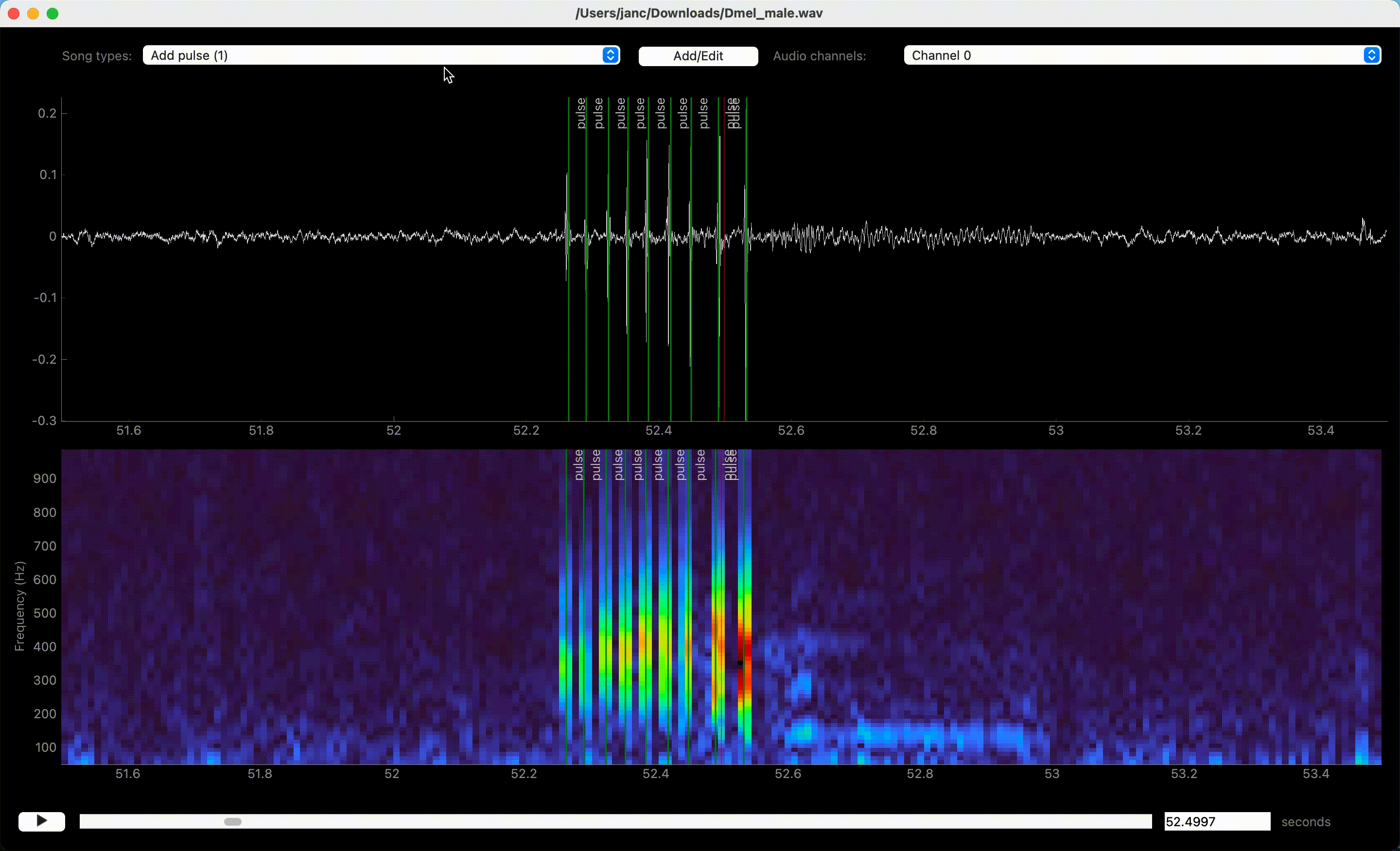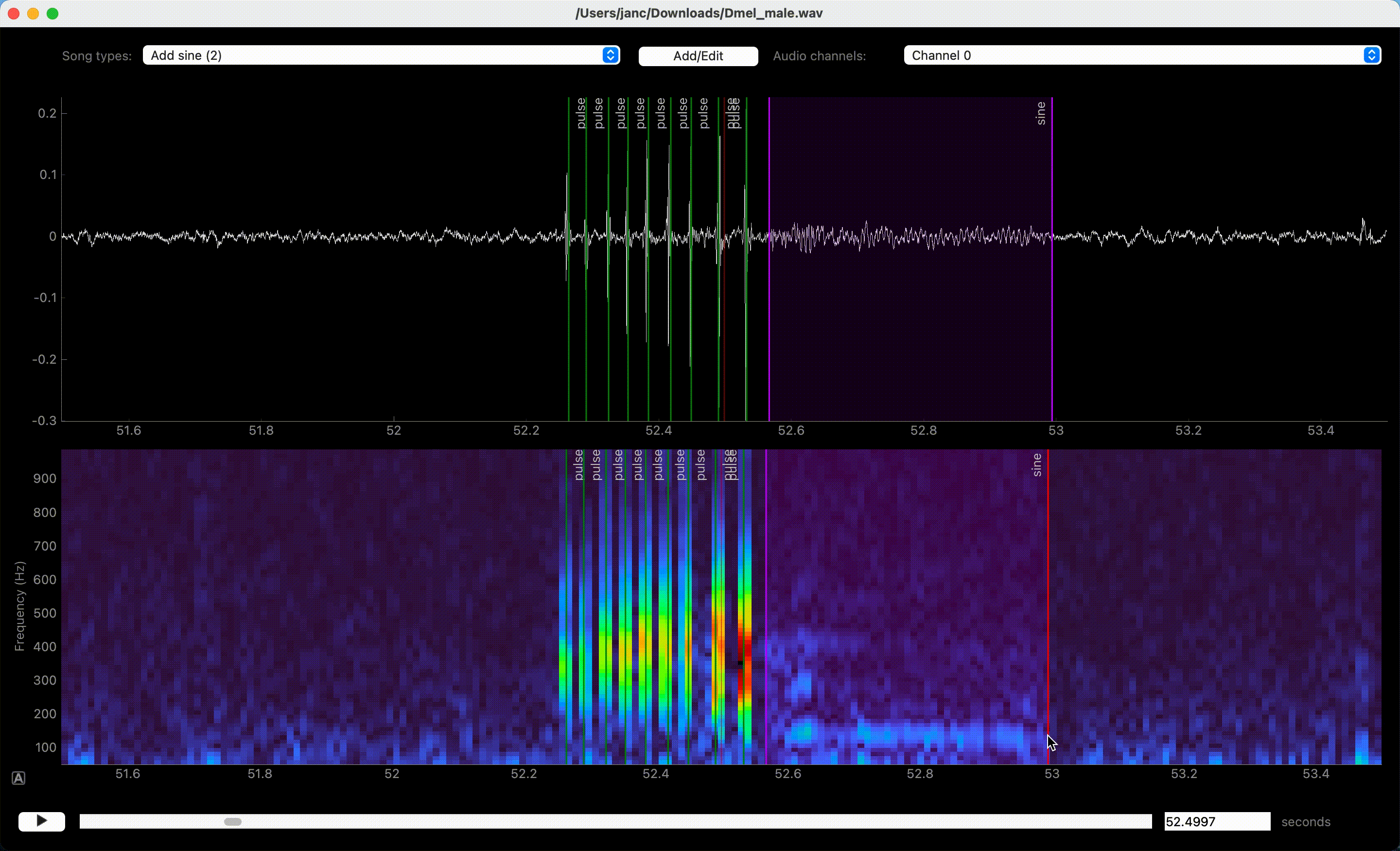
Left clicks in waveform or spectrogram few create annotations.#
Song is annotated by left-clicking the waveform or spectrogram view. If an event-like song type is active, a single left click marks the time of an event. A segment-like song type requires two clicks—one for each boundary of the segment.
Annotate by thresholding the waveform#
Annotation of events can be sped up with the “Thresholding mode”, which detects events as peaks in the sound energy that exceed a threshold. Activate thresholding mode via the Annotations/Toggle thresholding mode menu. This will display a draggable horizontal line - the detection threshold - and a smooth pink waveform - the energy envelope of the waveform. Adjust the threshold so that only “correct” peaks in the envelope cross the threshold and then press I to annotate these peaks as events.
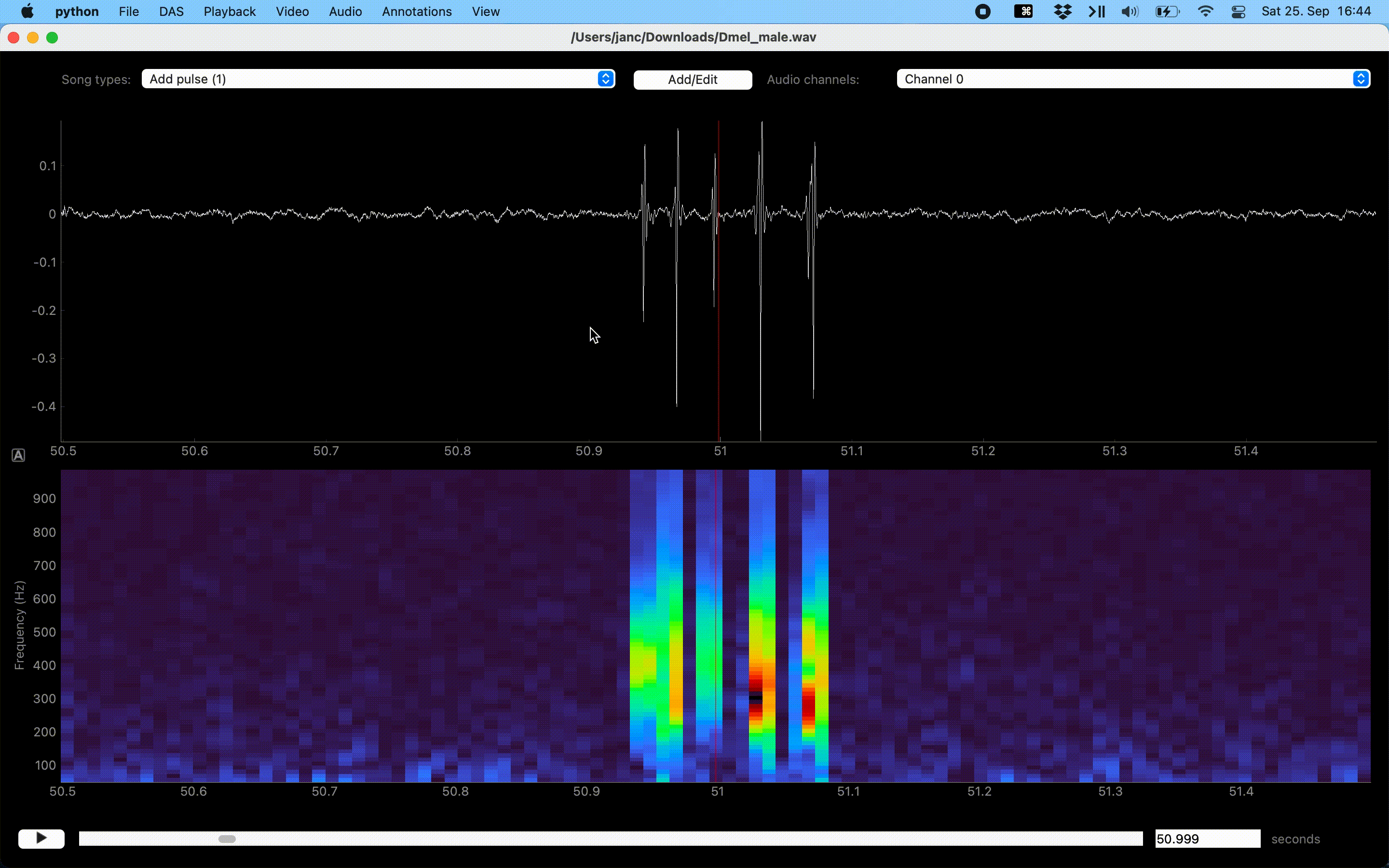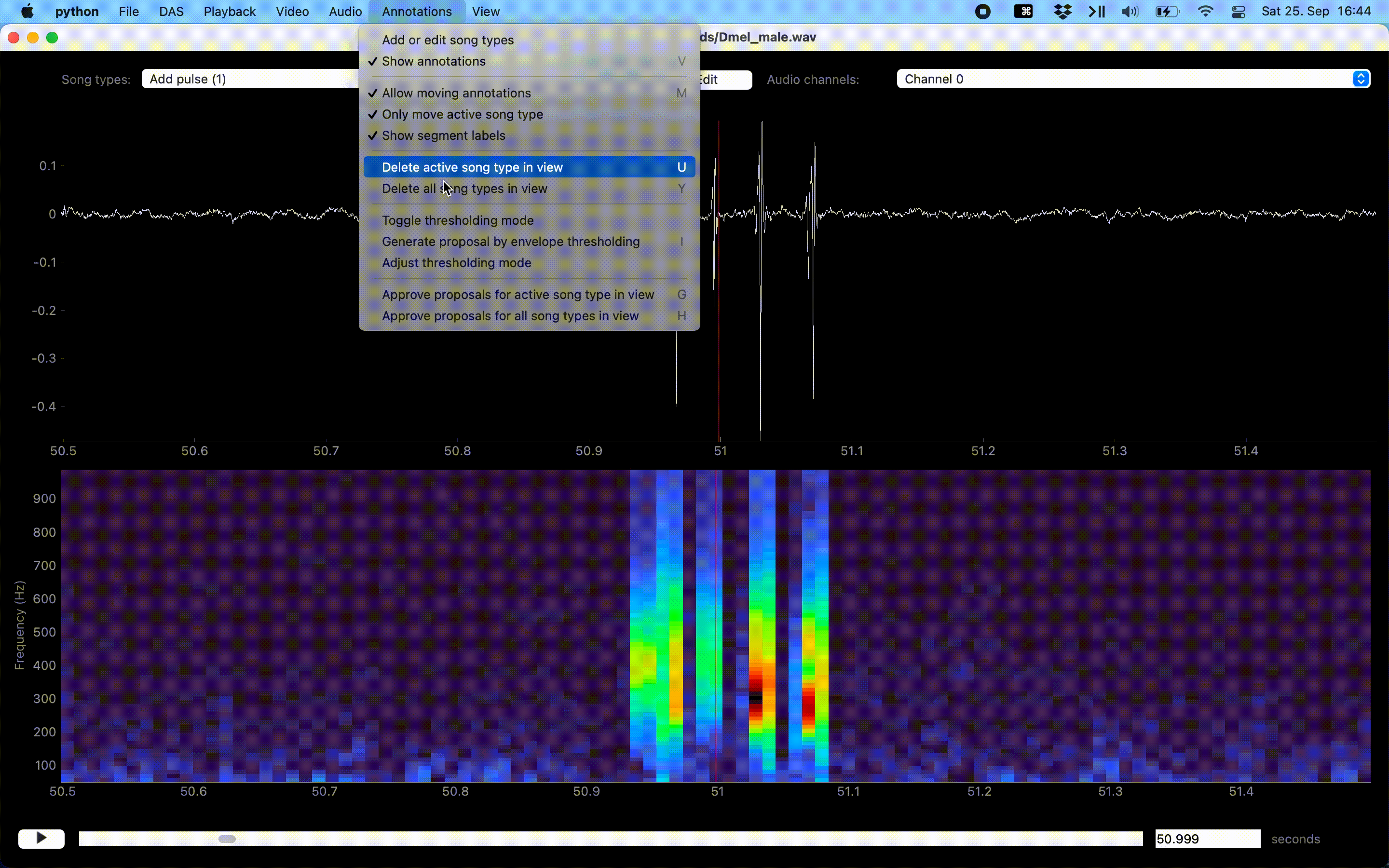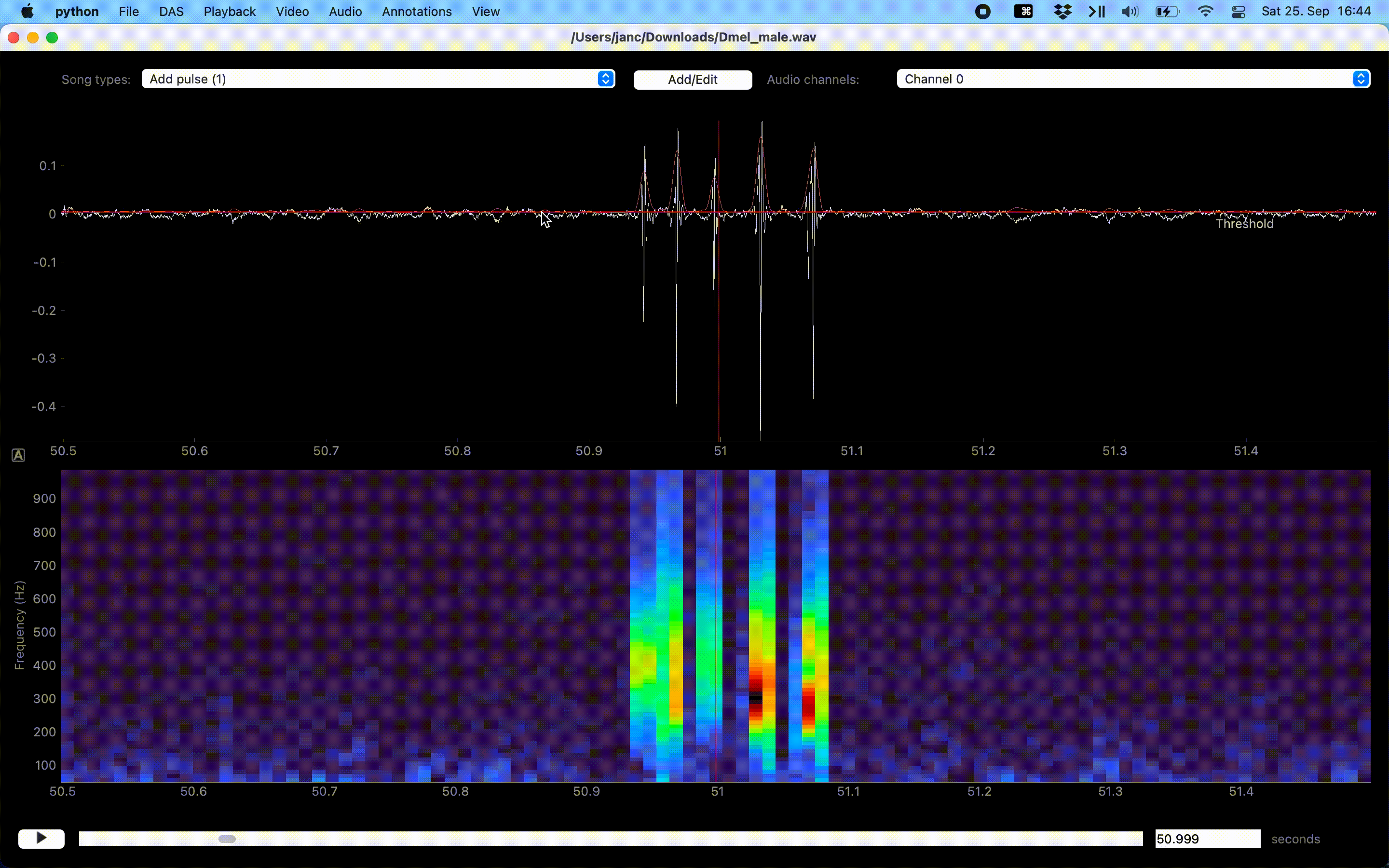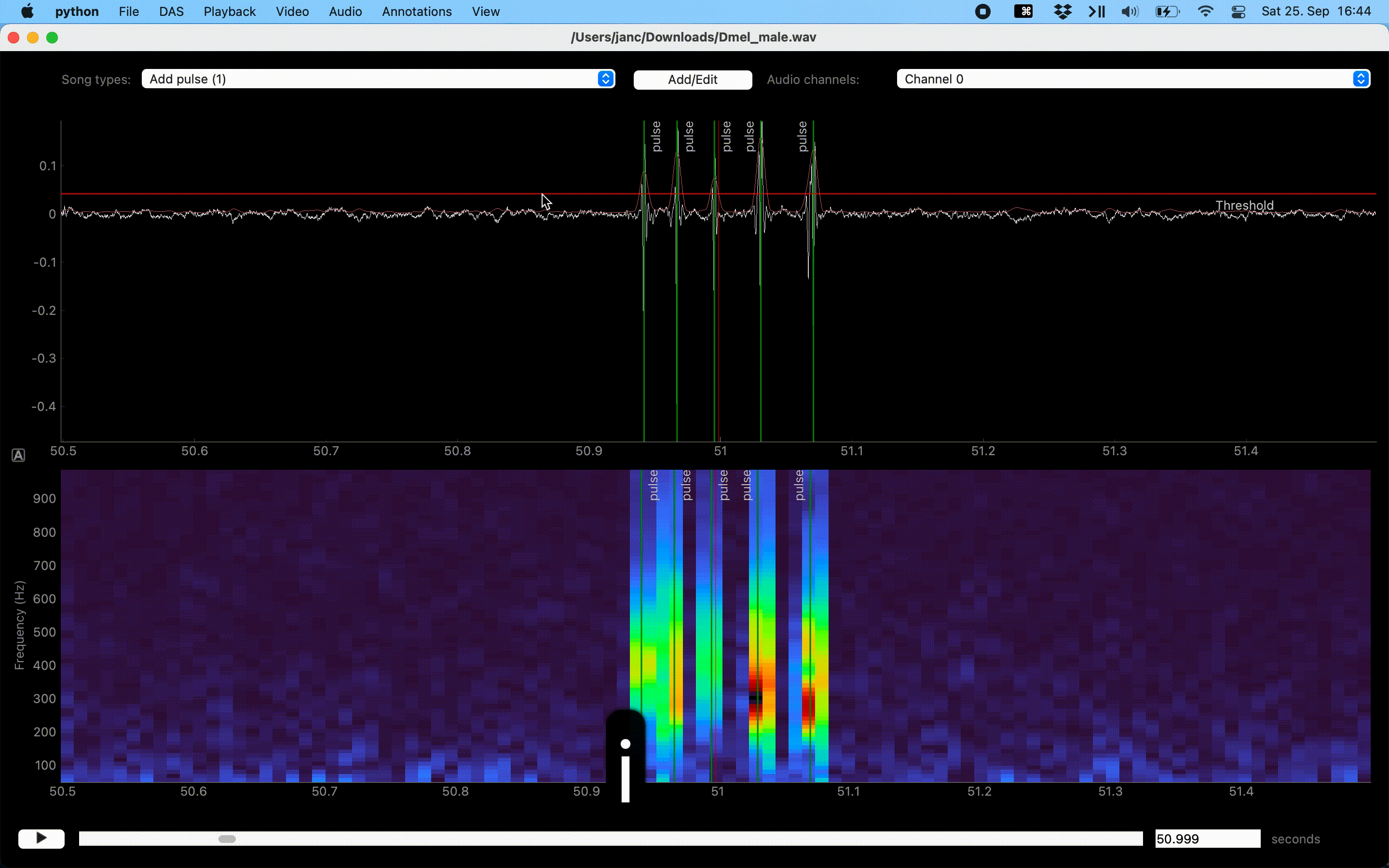
Annotations assisted by thresholding and peak detection.#
The detection of events can be adjusted via Annotations/Adjust thresholding mode:
Smoothing factor for envelope (seconds): Sets the width of the Gaussian used for smoothing the envelope. Too short and the envelope will contain many noise peaks, too long and individual events will become less distinct.
Minimal distance between events (seconds): If the events typically arrive at a minimal rate, this can be used to reduce spurious detections.
Edit annotations#
Adjust event times and segment bounds by dragging the lines or the boundaries of segments. Drag the shaded area itself to move a segment without changing its duration. Movement can be disabled completely or restricted to the currently selected annotation type in the Annotations menu.
Delete annotations of the active song type by right-clicking on the annotation. Annotations of all song types or only the active one in the view can be deleted with U and Y, respectively, or via the Annotations menu.
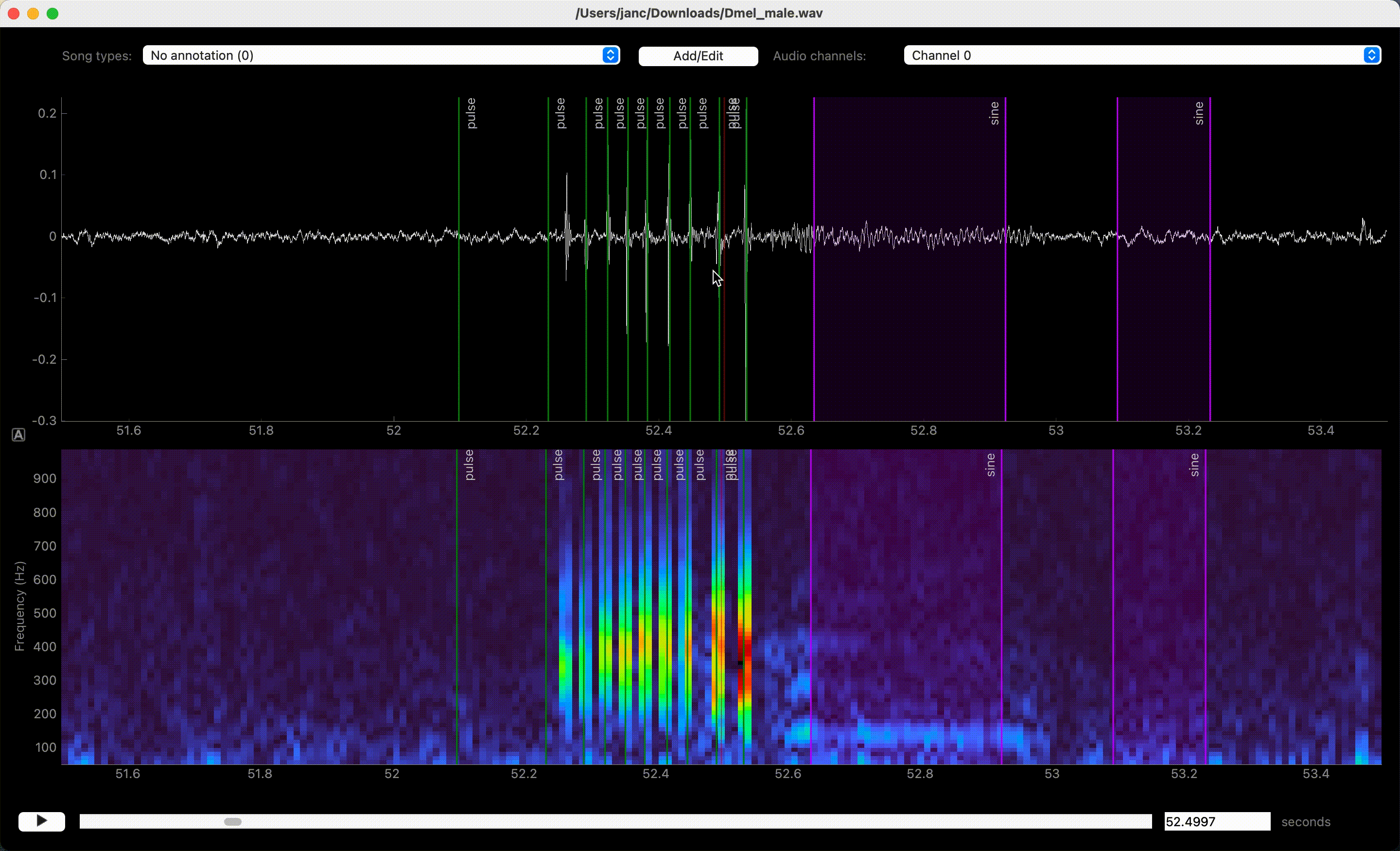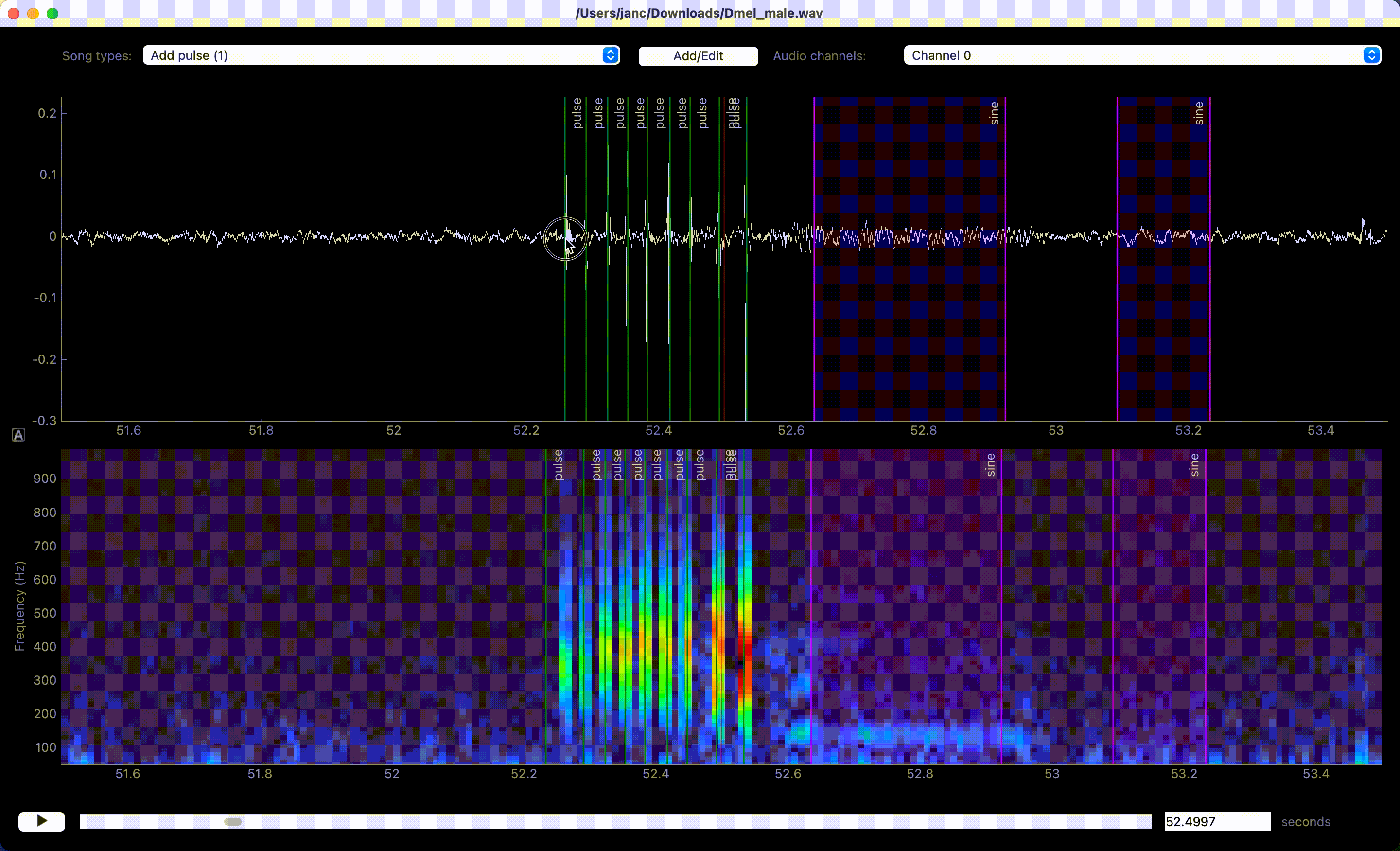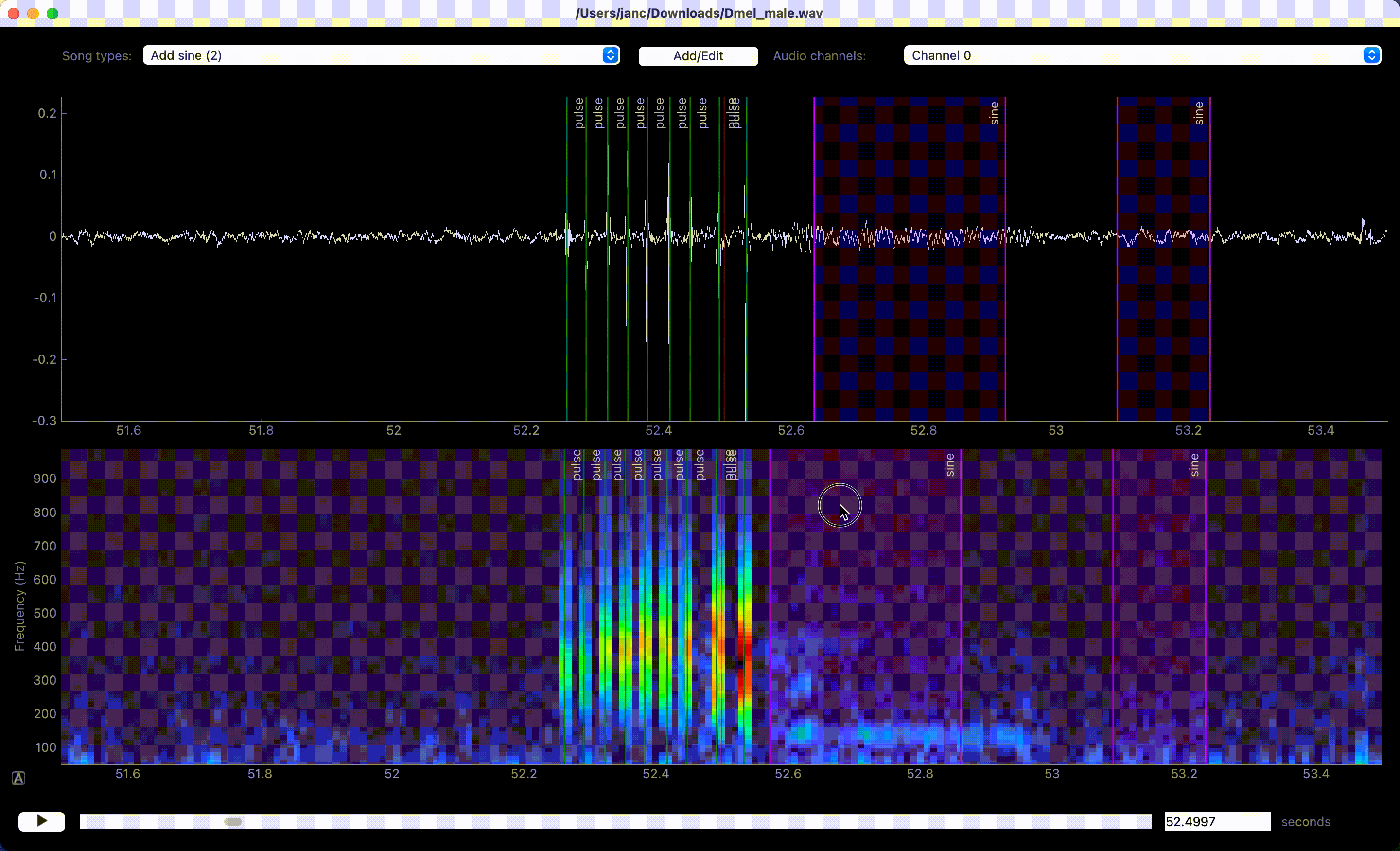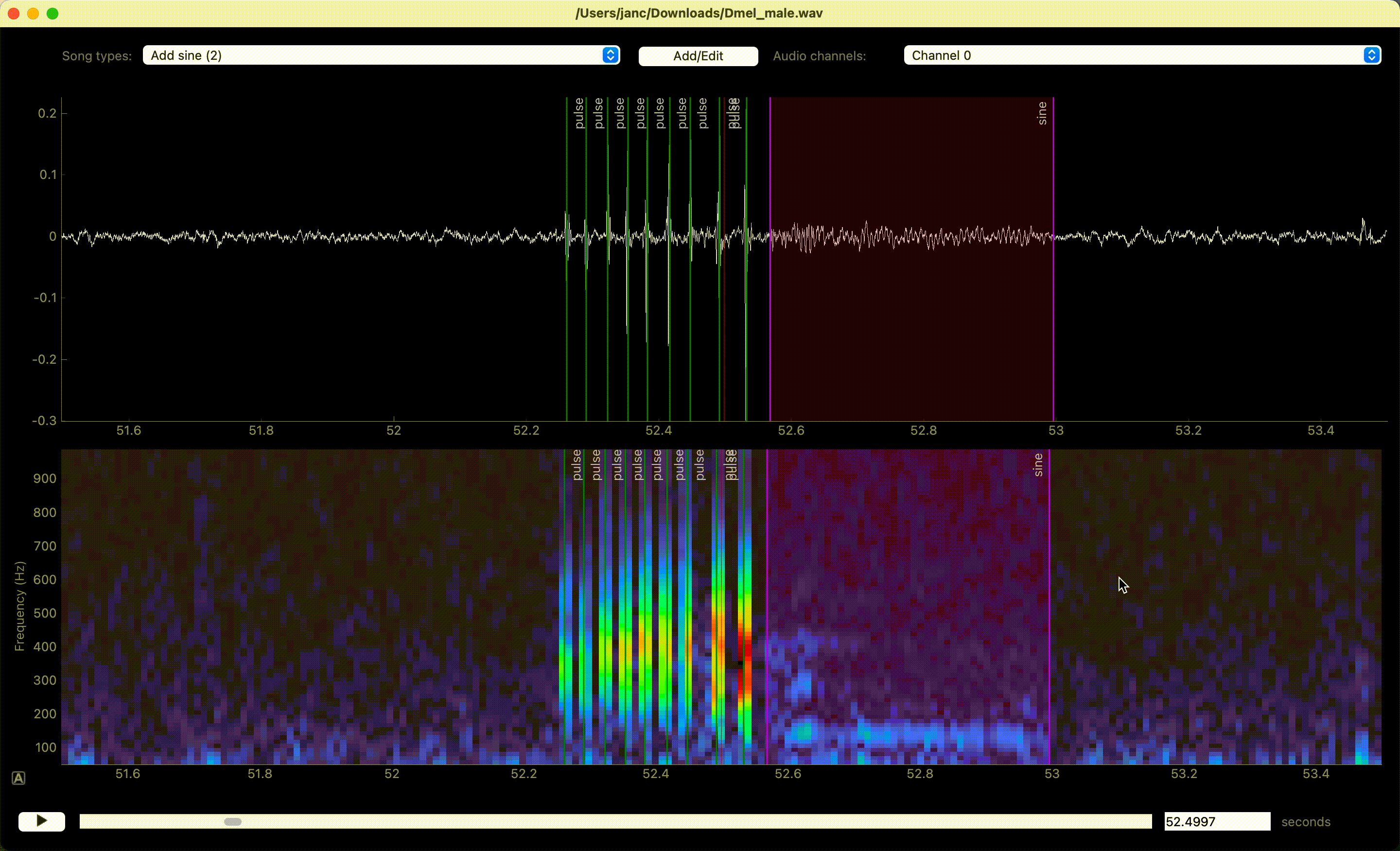
Dragging moves, right click deletes annotations.#
Change the label of an annotation via CMD/CTRL+Left click on an existing annotation. The type of the annotation will change to the currently active one.
Export and save annotations#
Export audio data and annotations for integration into a training dataset via File/Export for DAS. This will first ask you to select a folder. When making a training dataset, all exported data in the folder will be used, so make sure you do not save data from different projects to the same folder:
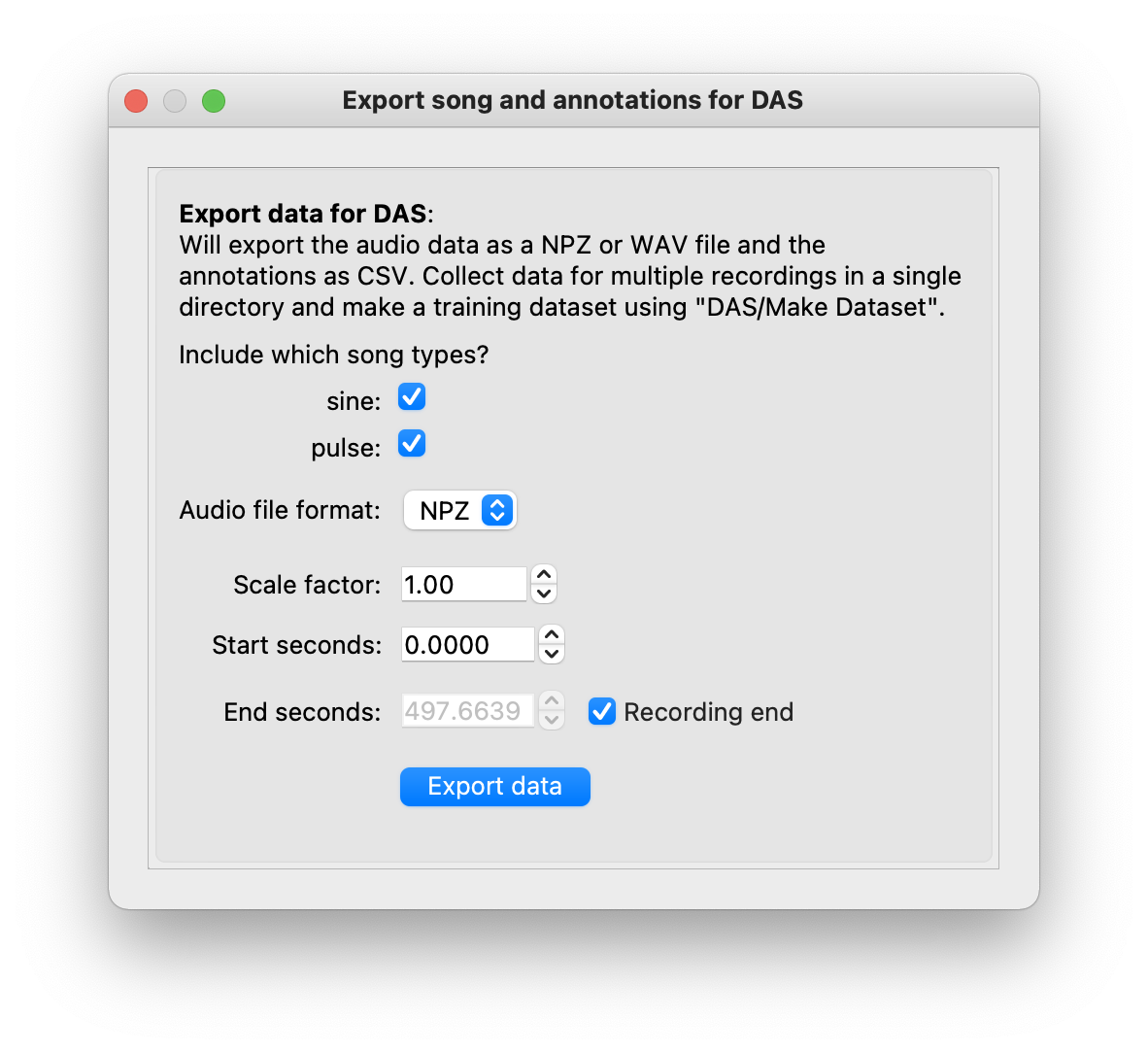
Export audio data and annotations#
After a folder has been selected, a dialog will open with options to customize the data export:
Song types to export: Select a specific song type to export annotations for. Predicting song in proof-read mode will produce song types ending in
_proposals- exclude these from the export. Annotations will be saved as a file ending in_annotations.csv(see a description of the format).Audio file format: The file format of the exported audio data:
NPZ: Zipped numpy variables. Will store a
datavariable with the audio and asampleratevariable.WAV: Wave audio file. More general but also less flexible format. For instance, floating point data is restricted to the range [-1, 1] (see scipy docs). Audio may need to be scaled before saving to prevent data loss from clipping.
Recommendation: Use NPZ—it is robust and portable.
Scale factor: Scale the audio before export. May be required when exporting to WAV, since the WAV format has range restrictions.
Start seconds & end seconds: Export audio and annotations between start and end seconds. Relevant when exporting partially annotated data. When training with small datasets, do not include too much silence before the first and after the last annotation to ensure that all parts of the exported audio contain annotated song.
Note
To generate a larger and more diverse dataset, annotate and export multiple recordings into the same folder. They can then be assembled in a single dataset for training (see next page).
Note
We also recommend you additionally save the full annotations next to the audio data via the File/Save annotations, since the exported annotations only contain the selected range. Saving will create a csv file ending in ‘_annotations.csv’, that will be loaded automatically the next time you load the recording.
Once data is exported, the next step is to train the network.